
Kolejka zadań
W tej części tutoriali zajmiemy się kolejkami zadaniowymi (ang. work queues), zwanymi w języku angielskim również jako task queues.
Zasadniczym celem tego przykładu jest pokazanie sposobu na uniknięcie natychmiastowego wykonywania zadań czasochłonnych i intensywnie wykorzystujących zasoby serwera, a także długiego czasu oczekiwania na ich realizację, co powodowałoby zablokowanie programu (ang. freeze) lub wyświetlenie ikony oznaczającej przetwarzanie żądania XMLHttpRequest (Ajax) przez długi czas.
Nikt nie lubi, gdy ikona przetwarzania jakiegoś zadania w tle wyświetla się zbyt długo.

Rozwiązaniem tego problemu jest umieszczenie zadań w kolejce, tak by czekały tam aż do pojawienia się wolnego „robotnika”.
Zadanie konwertowane jest do postaci komunikatu (w naszym przypadku – tekstowego), a następnie wysyłane jest do serwera RabbitMQ. Proces robotnika działający w tle pobiera z kolejki zadanie i je wykonuje/przetwarza.
Fabryka komunikatów i robotnicy
Komunikaty mogą mieć dowolną formę. „Robotników” możemy mieć wielu, dzięki czemu kolejka będzie mogła zostać szybciej rozładowana. Kolejne procesy pobierające komunikaty z serwera RabbitMQ będą dzielić pomiędzy siebie zadania do wykonania. Podejście to jest przydatne zwłaszcza w przypadku aplikacji internetowych, działających w asynchroniczny sposób, które na realizację konkretnego zadania mają bardzo mało czasu (pomiędzy wysłaniem żądania, a uzyskaniem odpowiedzi).
Opisaną powyżej sytuację ilustruje poniższy schemat:
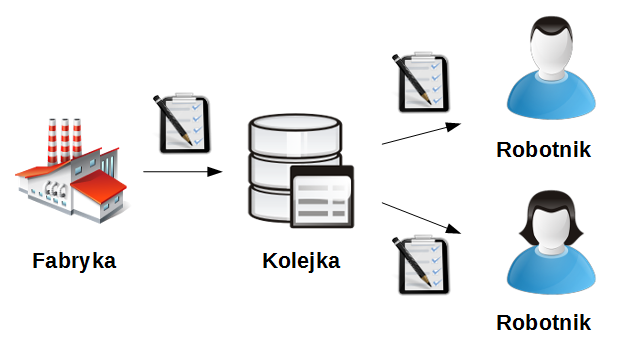
Fabryka-producent inicjuje zadania i przesyła je w postaci komunikatu do kolejki. Z niej poszczególni robotnicy-odbiorcy pobierają komunikaty, gdy są już „wolni” i wykonują wtedy zadanie według określonych wytycznych.
Zanim przystąpimy do pisania kolejnych programów potrzebujemy zaplanować co chcemy teraz osiągnąć.
W poprzednim tutorialu utworzyliśmy program nadaj.js, który wysyłał komunikat „Witajcie!”.
W tym przypadku również będziemy wysyłać do serwera RabbitMQ łańcuchy znaków, jednak będą one definiowane przez nas dynamicznie (ang. arbitrary messages).
Z powodzeniem możemy tutaj wysyłać dane np. w postaci formatu JSON lub innym, zdefiniowanym przez nas. Rozwiązanie jest elastyczne i tylko od nas zależy jego ostateczny kształt. Jednak, aby przedstawić ideę tego przykładu wysyłać będziemy krótkie komunikaty tekstowe, przekazywane do aplikacji fabryki-producenta jako parametr polecenia np.:
$ ./fabryka.js "Raz. Dwa. Trzy."
Aby zasymulować ciągłą pracę fabryki, wykorzystamy funkcję setTimeout() dostępną w języku JavaScript. Pozwala ona na opóźnianie wykonywania jednorazowego zadania, co wykorzystamy w programie odbierającym komunikat.
Ogólnie użycie funkcji setTimeout() wygląda następująco:
function delayedTask() {
console.log('Opóźnione zadanie wykonane po 3 sekundach');
}
setTimeout(delayedTask, 3000);Funkcja delayedTask() zostanie zostanie wykonana po 3 sekundach. W przypadku naszego programu odbierającego dane zasymulujemy właśnie tego typu opóźnienie, co ma symbolizować czasochłonność określonego zadania.
W tym celu do nadawcy komunikatu będziemy przekazywać w komunikacie kropki (.), z których każda będzie odpowiadała 1 sekundzie. Także użycie 2 kropek np. „Cześć. Mam na imię Adam. Co tam u Ciebie?” wywoła opóźnienie 2 sekund. Program fabrykę-producenta nazwiemy w tym przypadku fabryka.js
Program fabryka zadań
Program będziemy wywoływać na dwa sposoby:
$ ./fabryka.js
$ ./fabryka.js "Raz. Dwa. Trzy."Wykonując drugie polecenie potrzebujemy odczytać przekazywany do programu ciąg znaków – w tym przypadku „ Raz. Dwa. Trzy.”.
var msg = process.argv.slice(2).join(' ') || "Hello World!";W inicjalizacji zmiennej msg widzimy operację na process.argv zwracającej parametry wywołania programu jako tablicę łańcuchów znaków:
0. '/usr/bin/nodejs'
1. '/home/tom/projects/web/rabbitmq/nodejs/src/fabryka.js'
2. 'Raz. Dwa. Trzy.'"Metoda slice(2) wykonana na tablicy process.argv zwraca wszystkie parametry wywołania programu licząc od trzeciego elementu powyższej tablicy (numerowanej od zera), czyli w naszym przypadku:
['Raz. Dwa. Trzy.']Następnie na tej tablicy wywołujemy metodę join(' '), która konwertuje zawartość tablicy parametrów wywołania komendy do postaci łańcucha znaków.
Jako, że zasadniczą częścią programu fabryka.js jest wywołanie zwrotne (ang. callback) przyjrzyjmy się bliżej tej części programu:
var q = 'task_queue';
var msg = process.argv.slice(2).join(' ') || "Witamy!";
ch.assertQueue(q, {durable: true});
ch.sendToQueue(q, new Buffer(msg));
console.log(" [x] Wysłano '%s'", msg);Inicjujemy kolejkę o nazwie task_queue i ustalamy, że będzie to trwała kolejka: parametr durable jest ustawione
na true.
Kompletny kod fabryki-producenta wygląda następująco:
#!/usr/bin/env node
var amqp = require('amqplib/callback_api');
amqp.connect('amqp://localhost', function(err, conn) {
conn.createChannel(function(err, ch) {
var q = 'task_queue';
var msg = process.argv.slice(2).join(' ') || "Witamy!";
ch.assertQueue(q, {durable: true});
ch.sendToQueue(q, new Buffer(msg));
console.log(" [x] Wysłano '%s'", msg);
});
setTimeout(function() { conn.close(); process.exit(0) }, 500);
});Program robotnik
Kod programu odbierz.js, z pierwszego przykładu również wymaga pewnych zmian: powyżej przyjęliśmy, że pojedyncza kropka w treści komunikatu wysłanej przez fabrykę-producenta będzie opóźniała wykonanie zadania o jedną sekundę.
Zliczanie kropek odbywać się będzie następująco:
var secs = msg.content.toString().split('.').length - 1;Kod zmienionego fragmentu naszego programu-robotnika, modyfikujący program odbierz.js, który zapiszemy pod nazwą robotnik.js, a symulujący kilkusekundowe opóźnienie wygląda następująco:
ch.consume(q, function(msg) {
var secs = msg.content.toString().split('.').length - 1;
console.log(" [x] Odebrano %s", msg.content.toString());
setTimeout(function() {
console.log(" [x] Zrobione");
}, secs * 1000);
}, {noAck: true});Aby zobaczyć nasze programy w działaniu wystarczy w dwóch konsolach / terminalach wykonać poniższe komendy:
Terminal1 $ ./robotnik.js
Terminal2 $ ./fabryka.js"Obsługa kolejki za pomocą algorytmu karuzelowego
Napisano powyżej, że robotników-odbiorców zadań może być wielu. Pozwala to na równoległą pracę wielu procesów wykonujących czasochłonną pracę. Aby to zrobić wystarczy uruchomić więcej procesów programu robotnik.js w innych konsolach / terminalach. Pozwala to na proste skalowanie obsługi odbioru zadań.
Spróbujmy więc uruchomić nasz program robotnik.js w dwóch terminalach.
W pierwszym:
Terminal1 $ ./robotnik.js
[*] Oczekiwanie na wiadomości w task_queue.
Naciśnij CTRL+C aby zakończyć.W drugim:
Terminal2 $ ./robotnik.js
[*] Oczekiwanie na wiadomości w task_queue.
Naciśnij CTRL+C aby zakończyć.Teraz, skoro posiadamy działające procesy robotników potrzebujemy uruchomić program fabryki (fabryka.js) w trzecim terminalu. Aby zobaczyć sposób obsługi wielu odbiorców komunikatów uruchomimy kilkukrotnie aplikację producenta komunikatów:
Terminal3 $ ./fabryka.js "Pierwsza wiadomość."
Terminal3 $ ./fabryka.js "Druga wiadomość.."
Terminal3 $ ./fabryka.js "Trzecia wiadomość..."
Terminal3 $ ./fabryka.js "Czwarta wiadomość...."
Terminal3 $ ./fabryka.js "Piąta wiadomość....."Przyjrzyjmy się teraz działaniu programów-robotników. Pierwszy pracownik wyświetlił następujące odpowiedzi:
Terminal1 $ ./robotnik.js
[*] Oczekiwanie na wiadomości w task_queue.
Naciśnij CTRL+C aby zakończyć.
[x] Odebrano 'Pierwsza wiadomość.'
[x] Zrobione
[x] Odebrano 'Trzecia wiadomość...'
[x] Zrobione
[x] Odebrano 'Piąta.....'A drugi:
Terminal2 $ ./robotnik.js
[*] Oczekiwanie na wiadomości w task_queue.
Naciśnij CTRL+C aby zakończyć.
[x] Odebrano 'Druga wiadomość..'
[x] Zrobione
[x] Odebrano 'Czwarta wiadomość....'
[x] ZrobioneJak widzimy RabbitMQ wysyłał komunikaty na zmianę, raz do pierwszego pracownika, a raz do drugiego, w określonej kolejności: nieparzyste komunikaty odbierał pierwszy program, a parzyste drugi. W praktyce oznacza to, że oba programy odbiorą po połowie wszystkich żądań.
Ten sposób dystrybucji komunikatów pomiędzy wieloma odbiorcami nosi nazwę wysyłki za pomocą algorytmu karuzelowego (ang. round-robin dispatch). Aby lepiej zaobserwować jego działanie możemy uruchomić większą liczbę procesów-robotników.
W praktyce procesów tworzących zadania (fabryk-nadawców) również być wiele – wystarczy w kilku terminalach uruchomić polecenia w różnych konsolach / terminalach:
Terminal1 $ ./fabryka.js "Raz. Dwa. Trzy."
Terminal2 $ ./fabryka.js "Alfa. Beta. Gamma. Delta. Epsilon."
Terminal3 $ ./fabryka.js "Dziesięć. Jedenaście. Dwanaście."Zaś w kolejnych czterech program robotnik.js
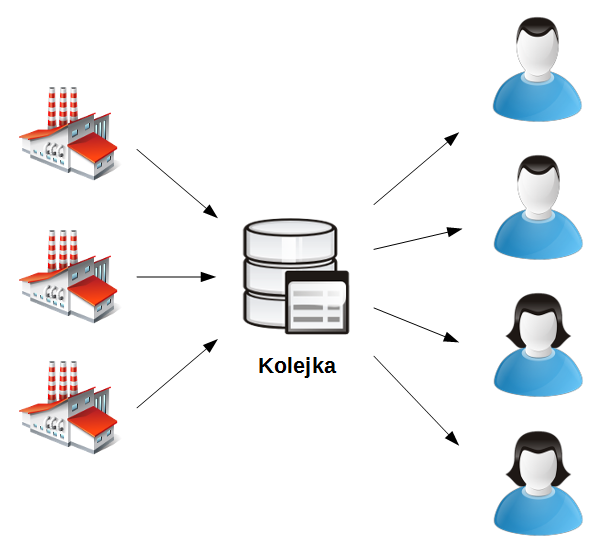
Powyższy przykład pokazuje trzy fabryki-producentów oraz czterech robotników-konsumentów.
W takiej sytuacji algorytm rozdzielający komunikaty pomiędzy odbiorców jest taki sam, jednak trudniej jest na tej podstawie zrozumieć jego działanie jeśli każdy program będzie wysyłał zadania do serwera RabbitMQ.
Potwierdzenie odebrania komunikatu
W trakcie omawiania dwóch programów z pierwszego przykładu wspomniano o potwierdzaniu otrzymania komunikatu (ang. ack(knowlegdement)). Domyślnie w systemie RabbitMQ potwierdzanie odbioru komunikatu jest wyłączone (noAck ma wartość true). Oznacza to, że jeśli aplikacja pobierająca dane z kolejki zakończy działanie w trakcie obsługi odebranego komunikatu – komunikat ten zostanie bezpowrotnie utracony!
Pierwsza wersja programu robotnik.js tak właśnie działa. Jeśli zatrzymamy proces robotnik.js w trakcie działania
(najlepiej zobaczyć to podczas odbioru komunikatu zawierającej pięć kropek, które czekają 5 sekund na zakończenie)
to przesłany komunikat zostanie bezpowrotnie utracony.
Aby to zmienić potrzebujemy zmodyfikować kod naszej aplikacji pracownika-odbiorcy w następujący sposób:
ch.consume(q, function(msg) {
var secs = msg.content.toString().split('.').length - 1;
console.log(" [x] Odebrano %s", msg.content.toString());
setTimeout(function() {
ch.ack(msg);
console.log(" [x] Potwierdzono odbiór");
}, secs * 1000);
}, {noAck: false});Poprawiony program zapiszmy jako porzadny-robotnik.js
Zmianie uległa konfiguracja parametru noAck – teraz ma wartość false, co oznacza, że program będzie potwierdzał odbiór komunikatu z kolejki. Dodatkowo, po odebraniu komunikatu musimy o tym poinformować serwer RabbitMQ, gdyż w przeciwnym wypadku komunikaty będą gromadziły się w kolejce i żadna z nich nie zostanie z niej usunięta.
Aby potwierdzić odbiór komunikatu wystarczy użyć metody ack() wywołanej na obiekcie kanału połączenia AMQP – w naszym przypadku przypisanego do zmiennej ch.
Metoda ta jako parametr przyjmuje obiekt komunikatu – tutaj – przechowywany jako msg.
Uruchamianie dwóch procesów pracowników robotnik.js w dwóch terminalach i wykonanie tej samej sekwencji tworzenia komunikatu przez program fabryki-producenta będzie wyglądało następująco.
Pierwszy pracownik wyświetlił następujące odpowiedzi:
Terminal1 $ ./porzadny-robotnik.js
[*] Oczekiwanie na wiadomości w task_queue.
Naciśnij CTRL+C aby zakończyć.
[x] Odebrano 'Pierwsza wiadomość.'
[x] Potwierdzono odbiór
[x] Odebrano 'Trzecia wiadomość...'
[x] Potwierdzono odbiór
[x] Odebrano 'Piąta wiadomość.....'
[x] Potwierdzono odbiórA drugi:
Terminal2 $ ./porzadny-robotnik.js
[*] Oczekiwanie na wiadomości w task_queue.
Naciśnij CTRL+C aby zakończyć.
[x] Odebrano 'Druga wiadomość..'
[x] Potwierdzono odbiór
[x] Odebrano 'Czwarta wiadomość....'
[x] Potwierdzono odbiórJeśli teraz zatrzymamy działanie jednego z robotników w trakcie wykonywania zadania (najlepiej widać to ponownie dla komunikatu zawierającego 5 kropek, która czeka 5 sekund na zakończenie działania), a drugi będzie nadal działał – to ów drugi program przejmie niepotwierdzony komunikat i przejdzie do opisanego w niej zadania.
Wygląda to następująco:
Terminal1 $ ./porzadny-robotnik.js
[*] Oczekiwanie na wiadomości w task_queue .
Naciśnij CTRL+C aby zakończyć.
[x] Odebrano 'Alfa. Beta. Gamma. Delta. Epsilon.'
^CNa drugim terminalu odbiorcy-robotnika zobaczymy:
Terminal2 $ ./porzadny-robotnik.js
[*] Oczekiwanie na wiadomości w task_queue .
Naciśnij CTRL+C aby zakończyć.
[x] Odebrano 'Alfa. Beta. Gamma. Delta. Epsilon.'
[x] Potwierdzono odbiórW języku angielskim takie zachowanie określa się jako redelivery, w języku polskim można je nazwać ponowną dystrybucją komunikatu. Przesłanie komunikatu do innego odbiorcy nie wiąże się z przekroczeniem czasu odpowiedzi (ang. timeout), co ma szczególne znaczenie w przypadku zadań o dłuższym czasie wykonania.
Można zadać pytanie – jeśli nie limit czasu na odpowiedź, to co informuje serwer RabbitMQ o tym, że dany komunikat należy ponownie przesłać? Otóż odpowiedź jest prosta – tzw. ponowna dystrybucja komunikatu ma miejsce, gdy połączenie pomiędzy kolejką, a odbiorcą zostanie zerwane, co może nastąpić między innymi w przypadku przerwania działania programu (wciśnięcie kombinacji CTRL+C, czy zabicie procesu robotnika). Inną przyczyną może być restart serwera, na którym działa program odbiorcy komunikatów.
Zatem jak widać – system RabbitMQ posiada odpowiednie mechanizmy zapobiegania utracie komunikatów.
Zapewnienie trwałości kolejce komunikatów
Jak już wiemy – komunikaty możemy chronić przed utratą w przypadku nieoczekiwanego zakończenia działania procesu odbiorcy-robotnika. Jednak funkcja potwierdzania odbioru zadania nie zapewnia nam bezpieczeństwa trwałości danych przesłanych przez nadawcę-producenta.
Przyczyną tego faktu jest to, że działanie samego serwera RabbitMQ może zostać przerwane. Może to mieć miejsce
w przypadku zatrzymania procesu kuriera komunikatów, jak i restartu samego serwera (wirtualnego i rzeczywistego).
W takiej sytuacji wszystkie zakolejkowane komunikaty, utworzone w sposób opisany powyżej zostaną utracone.
Aby uchronić się przed następstwami takiego zdarzenia możemy wskazać serwerowi RabbitMQ, aby trwale zapisywał komunikaty dodane do kolejki. Służy do tego parametr persistent, który domyślnie przyjmuje wartość false. W naszym przypadku chcemy, aby komunikaty były bezpieczne, więc ustawiamy wartość parametru na true.
Wystarczy w tym celu zmodyfikować jedną linię programu:
ch.sendToQueue(q, new Buffer(msg), {persistent: true});Tutaj należy się małe wyjaśnienie: otóż jeśli wcześniej zadeklarowaliśmy kolejkę o określonej nazwie, ale nie
ustawiliśmy parametru durable na true (albo parametr ten był pominięty, co jest domyślnym zachowaniem)
RabbitMQ zwróci nam błąd, bo nie pozwala on na tego typu operacje na kolejkach.
Warto dodatkowo mieć na uwadze, iż opisane powyżej metody dotyczące utrwalania komunikatów przesyłanych do kolejki nie dają 100% pewności, że komunikat mimo wszystko nie zostanie utracona.
Może mieć to miejsce w przypadku:
- gdy RabbitMQ zaakceptował odbiór komunikatu, ale nie zdążył go jeszcze zapisać na dysku;
- gdy dane nie są jeszcze fizycznie zapisane na dysku, gdyż RabbitMQ nie wykonuje operacji zapisu komunikatów na dysku dla każdego komunikatu oddzielnie – fsync(2), ale może je przechowywać w pamięci tymczasowej (cache), np. w pamięci RAM.
Opisane powyżej problemy mogą wystąpić w bardzo małych oknach czasowych, więc ryzyko ich wystąpienia jest minimalne.
Ich rozwiązaniem może być:
- użycie transakcji będących częścią standardu AMQP 0-9-1, co jednak znacząco ogranicza szybkość przekazywania komunikatu (transakcyjna komunikacja kanałem AMQP);
- lub wykorzystanie tzw. publisher confirms [26] , polegające na potwierdzeniu nadawcy (ang. publisher), iż dany komunikat dotarł do serwera RabbitMQ lub jego węzła oraz że została zapisana (oraz zreplikowana jeśli taka była konfiguracja).
Rozsądna dystrybucja komunikatów (ang. fair dispatch)
W przykładzie programów fabryka komunikatów – robotnik zostało powiedziane, iż komunikaty są rozdysponowywane naprzemiennie, raz do jednego odbiorcy, raz do drugiego.
W przypadku, gdy nieparzyste komunikaty będą zawierały czasochłonne zadania (w naszym przypadku: wiele kropek), a parzyste proste, niewymagające dużego nakładu – pierwszy robotnik stale będzie zajęty „ciężkimi pracami”, podczas gdy drugi może być nawet bezczynny. Taka obsługa komunikatów nie będzie działała tak, jakbyśmy sobie tego życzyli.
RabbitMQ wysyła komunikat do odbiorcy w momencie, gdy ten trafi do kolejki. Domyślnie robi to bezmyślnie wysyłając n-ty komunikat do n-tego odbiorcy, nie zwracając uwagi na liczbę potwierdzeń odbioru.
Aby to lepiej zilustrować wyobraźmy sobie listonosza, a konkretnie dwóch listonoszy. Obaj pobierają z placówki pocztowej listy, jednak jeden wozi je daleko (zadania czasochłonne), a drugi blisko. Ponieważ obydwaj pobierają z oddziału pocztowego co drugi komunikat, to pierwszemu ciągle przybywa zleceń do wykonania, a w związku z tym, że do realizacji każdego zadania potrzebuje dużo czasu – jego wydajność ciągle spada. Drugi natomiast po dostarczaniu komunikatów „marnuje czas” i czeka na swoją kolej.
Rozwiązaniem tego problemu jest użycie metody prefetch(n), która mówi ile komunikatów może zostać wstępnie
wysłanych do odbiorcy.
Użycie wartości 1 jako jej parametru oznacza, że w danym momencie RabbitMQ nie wyśle do odbiorcy więcej niż jeden komunikat aż do czasu, gdy ten wyśle potwierdzenia iż została ona prawidłowo przetworzona. W takim przypadku komunikat z zadaniem otrzyma pierwszy wolny robotnik.
Podanie zera mówi iż RabbitMQ może wysłać do odbiorcy nieograniczoną liczbę komunikatów, zaś użycie liczb większych niż 1 oznacza, iż takich komunikatów, wstępnie wysłanych do odbiorcy może być N. Licznik po stronie odbiorcy jest zależny od potwierdzania przetwarzanego komunikatu (wtedy kurier komunikatów może wysłać kolejną).
Ostateczny kod programu porzadny-robotnik.js:
#!/usr/bin/env node
var amqp = require('amqplib/callback_api');
amqp.connect('amqp://localhost', function(err, conn) {
conn.createChannel(function(err, ch) {
var q = 'task_queue';
ch.assertQueue(q, {durable: true});
ch.prefetch(1);
console.log(' [*] Oczekiwanie na wiadomości w:');
console.log('%s', q.queue);
console.log("Naciśnij CTRL+C aby zakończyć.");
ch.consume(q, function(msg) {
var secs = msg.content.toString().split('.').length - 1;
console.log(" [x] Odebrano %s", msg.content.toString());
setTimeout(function() {
ch.ack(msg);
console.log(" [x] Potwierdzono odbiór");
}, secs * 1000);
}, {noAck: false});
});
});Repozytorium z kodem źródłowym
Kod programów omawianych w tym tutorialu znajduje się pod adresem:
https://github.com/RattiQue/tutorials-pl-node.js

 Ta strona korzysta z plików cookies zgodnie z
Ta strona korzysta z plików cookies zgodnie z
Web Developer z ponad 8-letnim, komercyjnym doświadczeniem w tworzeniu stron i aplikacji internetowych oraz paneli administracyjnych w PHP, JavaScript, HTML i CSS.
Aktualnie zainteresowany architekturą mikroserwisów, które umożliwiają budowanie skalowalnych aplikacji internetowych.