
Do tej pory (jeśli podążasz za kolejnymi tutorialami) mieliśmy do czynienia tylko z kolejkami. Główną zasadą ich działania było to, że pojedynczy komunikat był przekazywany wyłącznie do jednego odbiorcy, co można porównać do przesyłania listów od nadawcy do odbiorcy.
W ten sposób można było lepiej rozłożyć przetwarzanie zadań w przypadku, gdy dysponowaliśmy większą liczbą robotników.
Teraz zajmiemy się czymś odrobinę bardziej złożonym, a mianowicie dostarczaniem tego samego komunikatu do wielu subskrybentów, czyli czymś w rodzaju dystrybucji prasy czy książek.
Producenta komunikatów będziemy nazywać wydawcą (ang. publisher), zaś konsumentów (odbiorców) komunikatów nazywać będziemy subskrybentami (ang. subscribers).
Centrala komunikatów
Komunikat jest przekazywany przez wydawcę: 
do centrali komunikatów (ang. exchange): 
Ta dodatkowa warstwa zwana jest w terminologii RabbitMQ pod angielskim słowem exchange, a w wolnym tłumaczeniu tablicą routing'u o określonej nazwie lub centralą komunikatów, nawiązującej pełnioną funkcją do centrali telefonicznych (ang. telephone exchange).
Podstawową cechą centrali komunikatów jest filtrowanie i/lub dyspozycja komunikatów na bazie określonych reguł.
Można to zrobić na kilka sposobów co zostanie pokazane w kolejnych częściach tutoriali.
Poniższy diagram ilustruje pełny przepływ komunikatów przetwarzanych przez RabbitMQ w centrali rozgłośni komunikatów (typu fanout):
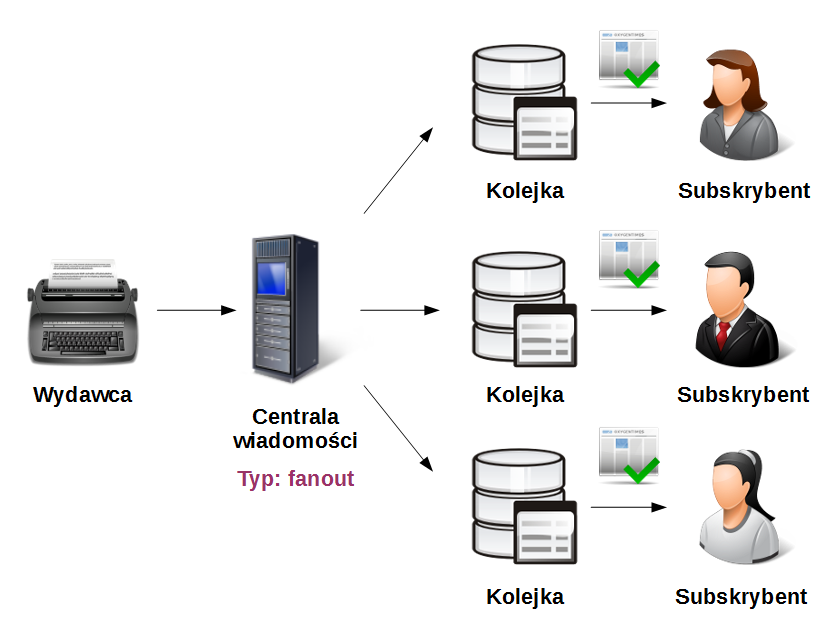
Główną różnicą w porównaniu do schematu omawianego wcześniej jest fakt, iż komunikat może zostać utracony, gdy nie ma żadnego subskrybenta, zatem komunikat nie jest odkładany w żadnej kolejce dla nieistniejącego odbiorcy.
Dzieje się tak, gdyż dla każdego odbiorcy tworzone są tymczasowe kolejki.
W ramach tego tutoriala napiszemy dwa programy:
- wydawca.js – publikujący nowe wydanie magazynu w centrali rozgłośni komunikatów,
- oraz czytelnik.js – subskrybujący treści przesyłane przez wydawcę, również korzystający z centrali rozgłośni komunikatów.
Program wydawca.js
W programie tym ponownie będziemy bazować na kodzie jaki stworzyliśmy w ramach poprzednich tutoriali, czyli rozszerzymy następujący program o nowe instrukcje:
#!/usr/bin/env node
var amqp = require('amqplib/callback_api');
amqp.connect('amqp://localhost', function(err, conn) {
conn.createChannel(function(err, ch) {
// nowe instrukcje
});
setTimeout(function() { conn.close(); process.exit(0) }, 500);
});Najpierw definiujemy nazwę centrali komunikatów:
var ex = 'empik';następnie tworzymy nowe wydanie jednego magazynu/kilku magazynów:
var date = new Date();
var issue = (date.getMonth() + 1) + '/' + date.getFullYear();
var msg = process.argv.slice(2).join(' ') || "aktualne wydanie " + issue;a na końcu publikujemy go/je w centrali typu fanout:
ch.assertExchange(ex, 'fanout', {durable: false});
ch.publish(ex, '', new Buffer(msg));
console.log(" [x] Wysłano: %s", msg);Cały program wydawca.js wygląda więc następująco:
#!/usr/bin/env node
var amqp = require('amqplib/callback_api');
amqp.connect('amqp://localhost', function(err, conn) {
conn.createChannel(function(err, ch) {
var ex = 'empik';
var date = new Date();
var issue = (date.getMonth() + 1) + '/' + date.getFullYear();
var msg = process.argv.slice(2).join(' ') || "aktualne wydanie " + issue;
ch.assertExchange(ex, 'fanout', {durable: false});
ch.publish(ex, '', new Buffer(msg));
console.log(" [x] Wysłano: %s", msg);
});
setTimeout(function() { conn.close(); process.exit(0) }, 500);
});
Jeśli teraz spróbujemy wydać jakiś magazyn np. aktualne wydanie
Terminal1 $ ./wydawca.js
[x] Wysłano: aktualne wydanie 3/2018
lub jedno z poprzednich:
Terminal1 $ ./wydawca.js 2/2016
[x] Wysłano: 2/2016
to rezultatem tego będzie utrata wysłanych komunikatów, gdyż – zgodnie z tym co powiedziano wcześniej – brak aktywnych subskrybentów komunikatów oznacza utracenie przesyłanych danych.
Program czytelnik.js
Napiszmy więc teraz program czytelnik.js
W nim ponownie bazujemy na kodzie źródłowym poprzednich programów-odbiorców:
#!/usr/bin/env node
var amqp = require('amqplib/callback_api');
amqp.connect('amqp://localhost', function(err, conn) {
conn.createChannel(function(err, ch) {
// nowe instrukcje
});
});Znowu definiujemy nazwę centrali komunikatów:
var ex = 'empik';i jej typ:
ch.assertExchange(ex, 'fanout', {durable: false});Następnie tworzymy tymczasową kolejkę, z której korzystać będzie wyłącznie pojedyncza instancja naszego program czytelinik.js:
ch.assertQueue('', {exclusive: true}, function(err, q) {
console.log(" [*] Oczekiwanie na wydanie w %s.", q.queue);
console.log(" Naciśnij CTRL+C aby zakończyć.");
ch.bindQueue(q.queue, ex, '');
ch.consume(q.queue, function(msg) {
console.log(" [x] Odebrano %s", msg.content.toString());
}, {noAck: true});
});Pełny kod źródłowy programu będzie wyglądał jak poniżej:
#!/usr/bin/env node
var amqp = require('amqplib/callback_api');
amqp.connect('amqp://localhost', function(err, conn) {
conn.createChannel(function(err, ch) {
var ex = 'empik';
ch.assertExchange(ex, 'fanout', {durable: false});
ch.assertQueue('', {exclusive: true}, function(err, q) {
console.log(" [*] Oczekiwanie na wydanie w %s.", q.queue);
console.log(" Naciśnij CTRL+C aby zakończyć.");
ch.bindQueue(q.queue, ex, '');
ch.consume(q.queue, function(msg) {
console.log(" [x] Odebrano %s", msg.content.toString());
}, {noAck: true});
});
});
});
Gdy teraz uruchomimy nasz program czytelnik.js zobaczymy, iż korzysta on z tymczasowej kolejki o wygenerowanej przez RabbitMQ nazwie np.
Terminal2 $ ./czytelnik.js
[*] Oczekiwanie na wydanie w amq.gen-RHJP1OPXQifo0ctvaDMFww.
Naciśnij CTRL+C aby zakończyć.
Pora teraz ponownie uruchomić program wydawca.js tak jak poprzednim razem:
Terminal1 $ ./wydawca.js
[x] Wysłano: aktualne wydanie 3/2018
Terminal1 $ ./wydawca.js 2/2016
[x] Wysłano: 2/2016
Terminal1 $ ./wydawca.js 5/2015 6/2015 9/2015
[x] Wysłano: 5/2015 6/2015 9/2015
W drugim terminalu zobaczymy działanie naszego czytelnika:
Terminal2 $ ./czytelnik.js
[*] Oczekiwanie na wydanie w amq.gen-RHJP1OPXQifo0ctvaDMFww.
Naciśnij CTRL+C aby zakończyć.
[x] Odebrano aktualne wydanie 3/2018
[x] Odebrano 2/2016
[x] Odebrano 5/2015 6/2015 9/2015
Jeśli teraz w trzeciej konsoli ponownie uruchomimy program czytelnik.js – zobaczymy – tak jak wcześniej wspomniano, iż system RabbitMQ przydzielił mu inną kolejkę niż programowi w drugim terminalu:
Terminal3 $ /czytelnik.js
[*] Oczekiwanie na wydanie w amq.gen-95Qaryoo-GWBXUQeZP01OQ.
Naciśnij CTRL+C aby zakończyć.
Tak więc z punktu nadawcy-wydawcy – nic się nie zmienia – choć nie wie on ilu odbiorców otrzymało przesłany komunikat lub czy ktokolwiek ją otrzymał. Inaczej wygląda to od strony subskrybenta.
Sytuację tą można zobrazować jeszcze w następujący sposób:
- posiadamy sieć komputerową składającą się z czterech komputerów, jednak jeden jest wyłączony;
- jeden z trzech komputerów pełni funkcję nadawcy,
- dwa pozostałe subskrybują kanał centrali komunikatów, do którego nadawca przesyła informacje;
- pierwsze komunikaty są wysyłane w momencie, gdy jeden komputer nie działa;
- kolejne, gdy jest on już włączony;
- a ostatnie, gdy znowu nie działa.
Gdybyśmy mieli przetrzymywać komunikaty dla początkowo wyłączonego komputera, a następnie je z nim synchronizować, to rezultatem takiego działania byłoby nieustanne zwiększanie ilości danych do przechowania i przesłania odbiorcy.
Takie podejście ma swoje plusy i minusy. Wszystko zależy od rodzaju komunikatów i tego co chcemy z nimi zrobić.
Jeśli byłyby to np. wiadomości przesyłane w ramach czata – nie moglibyśmy sobie pozwolić na ich utratę. Natomiast np. w przypadku logów aplikacji, czy usługi – możemy skorzystać z takiego rozwiązania zakładając, że zawsze będzie obecna co najmniej jedna aplikacja subskrybentów.
Przykładem takiego rozwiązania może być pobieranie logów i zapisywanie ich na dysku lub w bazie danych przez pierwszą aplikację-odbiorcę oraz drukowanie ich w konsoli / terminalu przez drugi program – gdy potrzebujemy zweryfikować działanie naszej aplikacji w różnych warunkach.
Przykładowe zastosowania
Centrale komunikatów typu fanout można stosować przy obsłudze:
- tabel wyników czy informacji o globalnych wydarzeniach w grach typu Massively Multiplayer Online (w skrócie MMO)
- informacji o wynikach sportowych oraz ich aktualizacjach przekazywanych w czasie „prawie rzeczywistym” na poświęconych temu serwisach internetowych przeznaczonych dla użytkowników urządzeń mobilnych oraz komputerów,
- rozproszonych systemów transmitujących aktualne informacje różnego rodzaju na temat zmian stanu określonych obiektów lub ich konfiguracji.
Repozytorium z kodem źródłowym
Kod programów omawianych w tym tutorialu znajduje się pod adresem:
https://github.com/RattiQue/tutorials-pl-node.js

 Ta strona korzysta z plików cookies zgodnie z
Ta strona korzysta z plików cookies zgodnie z
Web Developer z ponad 8-letnim, komercyjnym doświadczeniem w tworzeniu stron i aplikacji internetowych oraz paneli administracyjnych w PHP, JavaScript, HTML i CSS.
Aktualnie zainteresowany architekturą mikroserwisów, które umożliwiają budowanie skalowalnych aplikacji internetowych.